Welcome to my blog! I’m Jan Wilhelm T. Sy, a Computer Science student from Bicol University.
Over the past few weeks, I’ve had the incredible opportunity to undertake an On-the-Job Training (OJT) at Iraya Energies.
This experience will be a pivotal part of my academic journey, allowing me to apply and expand my knowledge in real-world settings.
Over the past few weeks, I’ve had the incredible opportunity to undertake an On-the-Job Training (OJT) at Iraya Energies.
This experience will be a pivotal part of my academic journey, allowing me to apply and expand my knowledge in real-world settings.
The
Beginning
Beginning
Welcome to my blog! This week marks the commencement of my On-the-Job Training (OJT) program, focusing on the development of a chatbot. From June 10, 2024, to 14, 2024, I engaged in the initial stages of this project, which aims to utilize data extracted from PDFs through an OCR (Optical Character Recognition) system.
During this first week, my primary objectives were to thoroughly understand the project's goals, conduct research on various language models, and outline the preliminary steps for creating an intuitive user interface. This foundational work is essential for the successful development of the chatbot, setting a strong groundwork for the tasks and challenges ahead. In this blog, I will share the insights and progress achieved during this crucial initial week.
During this first week, my primary objectives were to thoroughly understand the project's goals, conduct research on various language models, and outline the preliminary steps for creating an intuitive user interface. This foundational work is essential for the successful development of the chatbot, setting a strong groundwork for the tasks and challenges ahead. In this blog, I will share the insights and progress achieved during this crucial initial week.
ACTIVITY PERFORMED
During the first week of the mentorship program, I focused on orientation and initiation of research on assigned tasks, specifically chatbot development. This foundational work was crucial in setting the stage for the project.
Researched and Explored Language Models
Choosing the right language model is crucial for creating a chatbot because it dictates how well the bot can understand and respond to user inputs. OpenAI's GPT-3.5 Turbo is a popular choice in chatbot development, available through their APIs with some payment required. Fortunately, platforms like Hugging Face offer a variety of free and open-source language models from providers like Mistral AI, Microsoft, and Meta, providing developers with options that fit their project requirements.
In this research, I explored language models such as Mistral AI's Mistral-7B, Meta's LLaMA-3-8B, and Microsoft's Phi-3 family, all of which demonstrated impressive capabilities and efficiency. These models are lightweight and well-optimized, making them versatile for a wide range of applications. Among them, the Phi-3 mini is notable for its exceptionally small size, making it particularly suitable for environments with limited memory resources, yet it maintains robust performance.
In this research, I explored language models such as Mistral AI's Mistral-7B, Meta's LLaMA-3-8B, and Microsoft's Phi-3 family, all of which demonstrated impressive capabilities and efficiency. These models are lightweight and well-optimized, making them versatile for a wide range of applications. Among them, the Phi-3 mini is notable for its exceptionally small size, making it particularly suitable for environments with limited memory resources, yet it maintains robust performance.
Setting Up and Testing the Language Models
Using Python, I tested the language models with the Transformers library, Hugging Face Hub, and Pytorch. Loading models was straightforward with AutoModelForCausalLM and AutoTokenizer.from_pretrained. Continued conversations may slow down the model and increase memory usage.
Using the Language Models
Once our model was loaded, I followed the format specified in the model's documentation, typically a list of dictionaries containing user conversations and prompts. This dictionary is then passed as a parameter to the pipeline along with the generation arguments, which control the model's behavior. Subsequently, the model generates a response based on the provided prompts or queries.
I observed that when conversations continue, the language model may slow down when generating responses, particularly as it references the history of previous interactions before formulating answers to new prompts. This increased workload can also lead to runtime crashes due to high memory usage.
I observed that when conversations continue, the language model may slow down when generating responses, particularly as it references the history of previous interactions before formulating answers to new prompts. This increased workload can also lead to runtime crashes due to high memory usage.
Research on Improving the Language Models
Given the involvement of a database in our project, our team speculated that the database could potentially serve as a source of information when a user inputs a prompt to the chatbot (though this wasn't confirmed during our delayed orientation). I conducted research and studied Retrieval-Augmented Generation (RAG), exploring its potential to enhance language responses and investigating methods for its implementation.
Researched on Creating the User Interface
In chatbot development, a user interface is essential for interaction. As part of our mentorship plan, we'll use StreamLit for creating the chatbot's UI. Streamlit is an open-source Python library that simplifies app development with a straightforward API, ideal for building interactive web applications, including machine learning and data analysis tasks. It automates the conversion of Python scripts into web apps, making it easy to share and deploy user-friendly interfaces for various models and analyses.
I used the chat elements from StreamLit to create the user interface for the chatbot, it was fairly simple and straightforward to import and use as outlined in their documentation.
I learned that Streamlit has limited customization options for altering the styles of its components. Modifying or customizing components using CSS can be cumbersome and time-consuming. However, despite these challenges, it is still feasible to achieve some level of customization.
I used the chat elements from StreamLit to create the user interface for the chatbot, it was fairly simple and straightforward to import and use as outlined in their documentation.
I learned that Streamlit has limited customization options for altering the styles of its components. Modifying or customizing components using CSS can be cumbersome and time-consuming. However, despite these challenges, it is still feasible to achieve some level of customization.
Experimentation of ChatBot Implementation
I integrated the components to develop a functional prototype, ChatBot_V1, using the Phi-3 mini 4k instruct model, which performed well despite its small size.
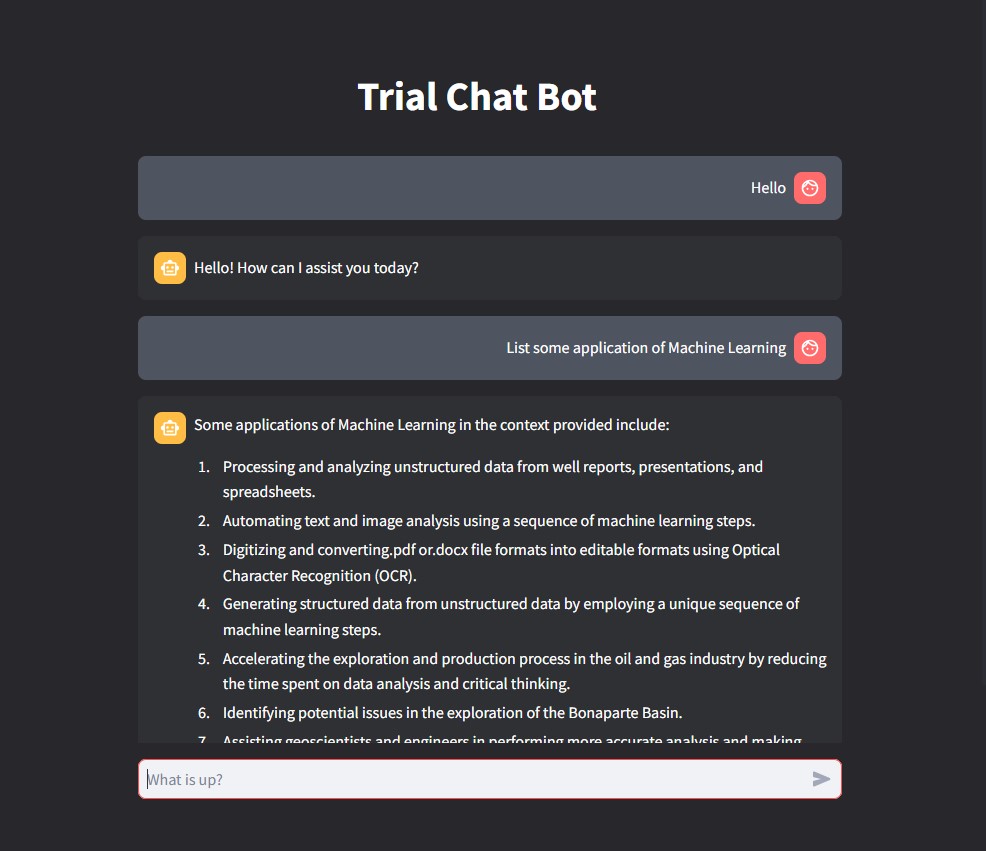
In conclusion, during the first week of my OJT, I primarily focused on research into chatbot development. I explored various language models such as Mistral AI's Mistral-7B and Meta's LLaMA-3-8B, testing them using Python and tools like Hugging Face's Transformers library. This research laid the groundwork for practical experimentation. Using what I learned, I conducted initial experiments in building a chatbot prototype. I utilized StreamLit for creating the user interface, despite its limited customization options. This hands-on experimentation allowed me to apply theoretical knowledge to practical development, marking a significant step forward in my learning process.